

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 네트워크 프로그래밍
- 캡슐화
- 충남 천안
- 언제나 휴일
- 안드로이드 앱 개발
- C++
- 프로젝트
- c#
- 실습으로 다지는 c#
- 동영상
- 소스 코드
- c언어
- 졸업 작품
- 언제나휴일
- 표준 입출력
- 산책하기 좋은 곳
- 클래스 다이어그램
- 실습
- 알고리즘
- 원격 제어 프로그램
- 유튜브 동영상 강의
- 무료 동영상 강의
- 강의
- 졸업 작품 소재
- 추천
- 동영상 강의
- 파이썬
- Windows Forms
- 소켓 통신
- 표준 라이브러리 함수
- Today
- Total
프로그래밍 언어 및 기술 [언제나휴일]
힙 정렬(Heap Sort) 알고리즘 본문
1. 알고리즘
힙 정렬은 힙 트리를 이용하는 알고리즘입니다. 최대 힙을 사용하면 크기 순(Ascend)으로 정렬하고 최소 힙을 사용하면 크기 역순(Descend)으로 정렬합니다.
힙 정렬은 먼저 힙 트리를 구성합니다. 그리고 루트의 값과 맨 마지막 값을 교환한 후에 정렬 범위를 1 줄입니다. 이와 같은 작업을 반복하여 정렬 범위가 1일 때까지 반복합니다.
최대 힙 트리에서 루트는 최대 값을 갖습니다. 따라서 마지막 값과 교환하면 제일 큰 값이 맨 뒤로 배치할 수 있습니다. 그리고 난 후에 정렬 범위를 줄여나가면 최종적으로 정렬 상태를 만들 수 있는 것입니다.
힙 정렬(base:배열의 시작 주소, n: 원소 개수, compare:비교 논리)
초기 힙 구성
루트와 맨 마지막 자손 교환
n을 1 감소
반복(n: n->1)
힙 구성루트와 맨 마지막 자손 교환
n을 1 감소
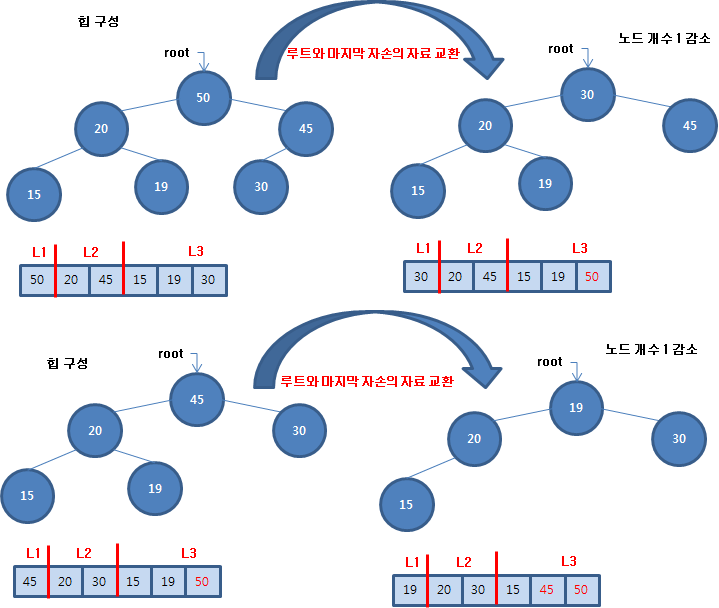
힙을 구성하는 방법은 초기에 힙을 구성하는 방법과 루트와 마지막 자식을 교환한 후에 루트에 있는 자료를 힙 트리 논리에 맞는 자리를 찾는 방법이 있습니다.
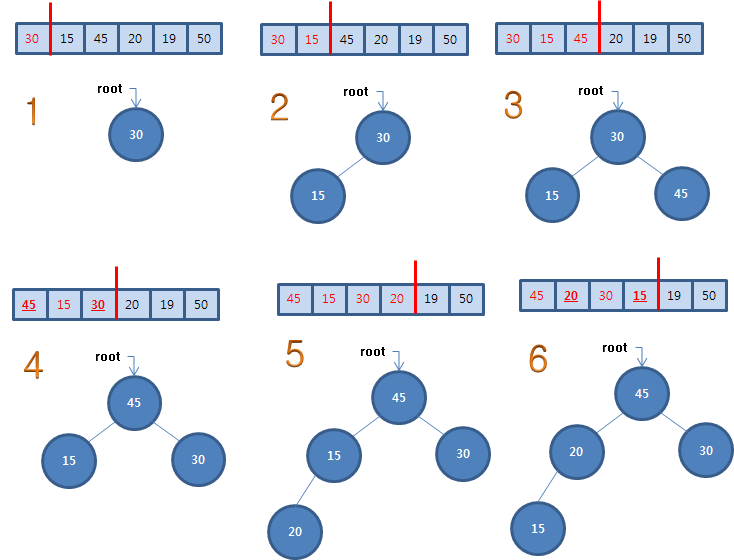
먼저 초기에 힙을 구성하는 방법을 순차적으로 힙 트리에 추가하는 과정으로 진행합니다. 새로 추가하는 노드는 부모와 크기를 비교하여 추가할 자료의 값이 더 크면 부모와 자료를 교환해 나갑니다. 만약 부모가 더 크면 자리를 찾은 것입니다.
이를 의사코드로 표현하면 다음과 같습니다.
초기 힙 구성(base:배열의 시작 주소, n: 원소 개수, compare:비교 논리)
반복(i:1->n)
j:=1
반복(j>0)
pa:=PARENT(j)
조건: compare(base[j], base[pa])이 0보다 크면
base[j], base[pa] 교환
j: = pa
아니면
내부 루프 탈출
루트와 마지막 자손 노드의 자료를 교환한 후에 노드 개수를 1 감소한 후에 루트에 있는 자료를 배치하는 것은 자식들 값 중에 큰 값과 비교하여 자신의 값이 작을 때 교환해 나가는 것을 반복합니다. 만약 자식이 없거나 자신이 자식들 값보다 크거나 같으면 작업은 끝납니다. 자식이 없거나 자식이 왼쪽만 있을 수 있으며 이를 고려한 의사 코드는 다음과 같습니다.
힙 구성(base:배열의 시작 주소, n: 원소 개수, compare:비교 논리)
반복
lc:= LCHILD(me)
rc:= RCHILD(me)
자식이 없으면
탈출
조건 왼쪽 자식만 있을 때
조건 compare(base[me],base[lc])>0일 때
base[me], base[lc] 교환
탈출
bc := 왼쪽 자식과 오른쪽 자식 중에 자료가 큰 값의 인덱스
조건 compare(base[bc],base[me])>0일 때
base[bc],base[me] 교환
아니면
탈출
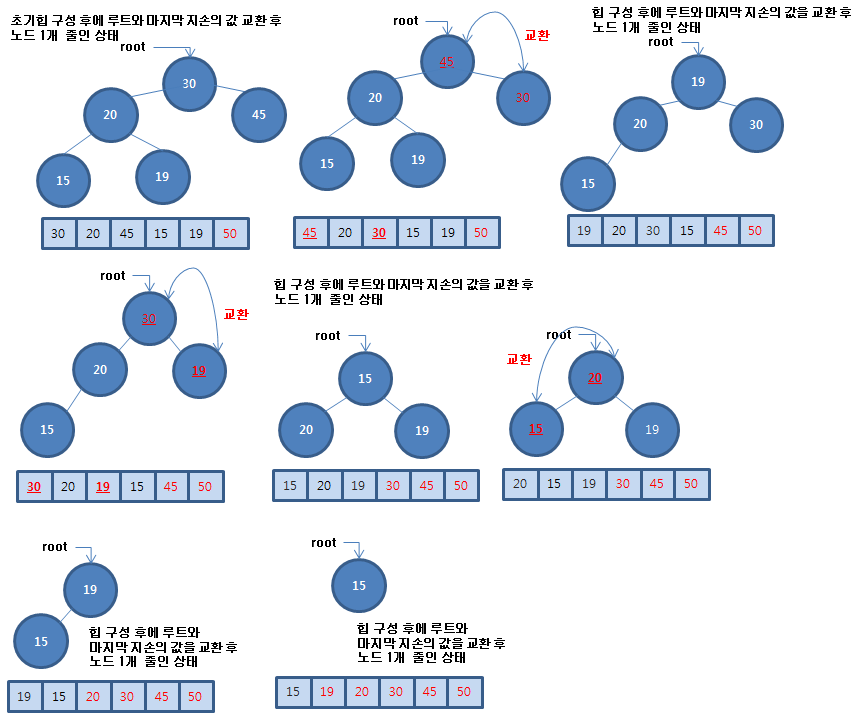
2. 점근식 계산
먼저 초기 힙 구성하는 시간을 계산해 보기로 해요.
초기 힙 구성은 내부 반복문을 n번 수행합니다. 그리고 내부 반복문은 트리 높이에 따라 비용이 차이가 생기는데 맨 마지막 자료를 구성할 때 걸리는 시간이 최악입니다. 그리고 맨 마지막 자료를 구성할 때 부모와 비교하면서 교환하기 때문에 최악일 때 비교와 교환을 트리의 높이만큼 진행합니다. 따라서 logN보다 작습니다. 따라서 초기 힙 구성 비용은 최악일 때도 NlogN보다 작습니다.
초기 힙 구성 비용 ≤ NlogN
힙 구성은 N-1 번 수행합니다. 그리고 힙 구성에 걸리는 비용은 트리의 높이가 제일 높을 때 최악이 나옵니다. 자식과 비교하면서 교환하므로 logN에 비례합니다. 따라서 전체 힙 구성에 걸리는 비용의 합은 NlogN보다 작습니다.
전체 힙 구성에 걸리는 비용의 합 ≤ Nlog(N)
따라서 힙 정렬에 드는 비용은 초기 힙 구성 비용(Nlog(N)보다 작음)과 전체 힙 구성에 걸리는 비용(NlogN보다 작음)이므로 2NlogN보다 작다고 할 수 있습니다. 따라서 빅 오 점근식 표기법으로 표현한다면 상수를 제거하여 O(NlogN)이라고 말할 수 있습니다.
일반적으로 퀵 정렬이 가장 빠르다고 알려졌지만 선택한 피벗의 성질에 따라 다른 성능을 보이기 때문에 실제로 가장 빠른 것은 아닙니다. 오히려 힙 정렬은 자료의 성질과 관계없이 안정적으로 O(NlogN)을 보장합니다. 이 외에도 앞으로 다룰 병합 정렬과 기수 정렬도 O(NlogN)성능을 보장하는 정렬 방식입니다.
3. 소스 코드
//힙 정렬(Heap Sort)
#include <stdio.h>
#define LEFT_CHILD(x) (2*x + 1)
#define RIGHT_CHILD(x) (2*x + 2)
#define PARENT(x) ((x-1)/2)
#define SWAP(a,b) {int t; t = a; a=b; b=t;}//a와 b를 교환
void HeapSort(int *base, int n);
void ViewArr(int *arr, int n);
int main(void)
{
int arr[10] = { 9,4,3,10,5,8,7,6,2,1 };
ViewArr(arr, 10);
HeapSort(arr, 10);
ViewArr(arr, 10);
return 0;
}
void InitHeap(int *base, int n);
void MakeHeap(int *base, int n);
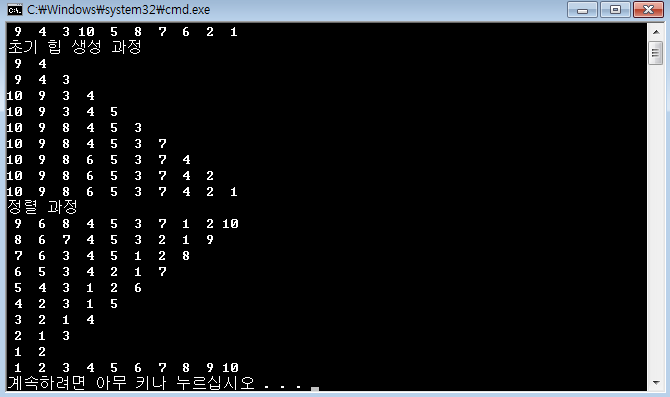
void HeapSort(int *base, int n)
{
int on = n;
printf("초기 힙 생성 과정\n");
InitHeap(base, n);
n--;
SWAP(base[0], base[n]);
printf("정렬 과정\n");
while (n>1)
{
MakeHeap(base, n);
ViewArr(base, n + 1);
n--;
SWAP(base[0], base[n]);
}
ViewArr(base, n + 1);
}
void InitHeap(int *base, int n)
{
int pa = 0;
int now;
int i;
for (i = 1; i<n; i++)//순차적으로 힙에 구성
{
now = i;
while (now>0)//now의 인덱스가 0이 아니면(힙의 루트가 아니면)
{
pa = PARENT(now);//부모 인덱스 구함
if (base[now]>base[pa])//부모보다 더 크면
{
SWAP(base[now], base[pa]);//부모와 교환
now = pa;//인덱스를 부모로 설정
}
else//아니면 자리를 찾은 것임
{
break;
}
}
ViewArr(base, i + 1);
}
}
int FindMaxIndex(int *base, int n, int now);
void MakeHeap(int *base, int n)
{
int now = 0;
int mp = 0;
//루트에 있는 요소를 힙 트리에 맞게 자리를 찾는 과정
while (LEFT_CHILD(now) < n)//왼쪽 자식이 있다면
{
int mp = FindMaxIndex(base, n, now);//now와 왼쪽, 오른쪽 자식 중에 큰 값의 위치 찾음
if (mp == now)//mp와 now가 같으면
{
break;//자리를 찾은 것임
}
SWAP(base[mp], base[now]);//now와 큰 값의 자리 교환
now = mp;//큰 값의 위치를 now로 설정
}
}
int FindMaxIndex(int *base, int n, int now)
{
int lc = LEFT_CHILD(now);//왼쪽 자식
int rc = RIGHT_CHILD(now);//오른쪽 자식
if (rc >= n)//오른쪽 자식이 없을 때
{
if (base[now]<base[lc])
{
return lc;
}
return now;
}
if (base[lc]<base[rc])
{
return rc;
}
return lc;
}
void ViewArr(int *arr, int n)
{
int i = 0;
for (i = 0; i<n; i++)
{
printf("%2d ", arr[i]);
}
printf("\n");
}'C & C++ > C언어 예제 및 소스' 카테고리의 다른 글
| 스택을 연결리스트로 구현 (0) | 2024.01.09 |
|---|---|
| 스택 - 버퍼크기 자동 확장 (1) | 2024.01.08 |
| 스택 - 버퍼 동적 할당 (1) | 2024.01.07 |
| 스택 - 버퍼 크기 고정 (1) | 2024.01.06 |
| 병합 정렬(합병 정렬, Merge Sort) 알고리즘 (1) | 2024.01.04 |
| 퀵 정렬 (Quick Sort) (1) | 2024.01.03 |
| 삽입 정렬 (Insertion Sort) (1) | 2024.01.02 |
| 선택 정렬 (Selection Sort) 알고리즘 (0) | 2024.01.01 |



